谷歌开源语音识别AI技术,可以从人群中区分每个人的发言

虽然机器语音识别的准确率已经很高,但是从一群人嘈杂的沟通交流中区分每个人说了什么,对于机器来说还是一个艰巨的挑战。Speaker Diarization(发言者语音片段切分归类)是一个将群组发言中不同人不同时间点的语音样本划分和重组为独特的,同质的片段的过程,分离出谁在何时说了什么,这对机器来说可不像人类那么容易,通过训练机器学习算法来执行的难度也比想象的大很多。因为强大的Diarization系统必须能够将新个体与之前未遇到的语音片段相关联。
但谷歌的人工智能研究部门在Diarization的高性能模式上取得了令人鼓舞的进展。在一篇新论文(“ 全监督演讲者Diarization ”)和随附的博客文章中,谷歌研究人员描述了一种新的人工智能(AI)系统,该系统“可以以更有效的方式利用受监督的发言人标签”。
该论文的作者声称核心算法实现了对于实时应用程序而言足够低的在线分类错误率(DER) – 在NIST SRE 2000 CALLHOME基准测试中为7.6%,而谷歌之前的方法为8.8%DER – 目前源代码已经在Github上开源。
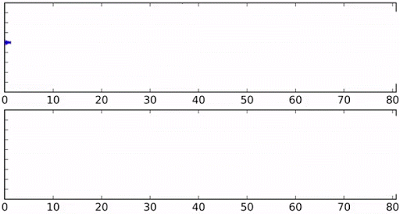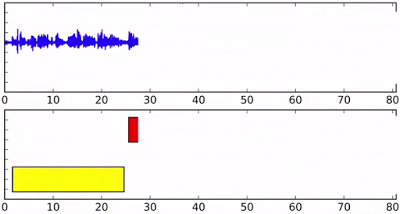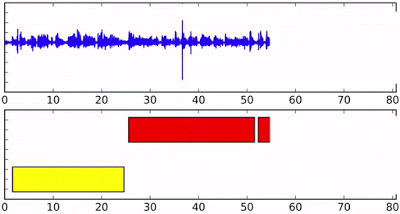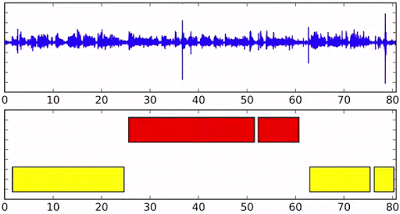
上图:流式音频上的发言人分类,底部轴的不同颜色表示不同的发言人。
谷歌研究人员的新方法通过递归神经网络(RNN)模拟发言者的嵌入(即,单词和短语的数学表示),RNN是一种机器学习模型,可以使用其内部状态来处理输入序列。每个发言者都以自己的RNN实例开始,该实例在给定新嵌入的情况下不断更新RNN状态,使系统能够学习在发言者和话语之间共享的高级知识。
“由于该系统的所有组件都可以以监督的方式学习,因此在可以获得具有高质量时间标记的扬声器标签训练数据的情况下,优于无监督系统,”研究人员在论文中写道。“我们的系统采用全面监督,并且能够从带有时间标记的发言者标签的示例中学习。”
在未来的工作中,团队计划优化模型,以便它可以集成上下文信息以执行离线解码,他们期望这能进一步降低DER错误率。谷歌团队还准备直接对声学特征进行建模,以便整个发言者diarization系统可以进行端到端的训练。
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者CashCat

















