找到趁手的锤子:如何正确选择机器学习算法?(附信息图)
机器学习是艺术和科学的结合。当你研究机器学习算法时,会发现没有一种解决方案或一种算法适合所有人。选择机器学习算法时需要考虑很多因素。
有些问题非常具体,需要采取独特的方法。例如推荐系统,这是一种非常常见的机器学习算法,它解决了一个非常具体的问题。但是很多问题非常开放,需要不断的试验和试错。监督学习,分类和回归等都属于非常开放的算法,可以用于异常检测,也可以用于构建更加通用的预测模型。
我们在选择机器学习算法时,更多考虑的应该是业务需求,而不是算法优化或技术方面的因素。为了帮助大家缩小算法搜索半径,我们介绍一下机器学习算法选择的要点,同时还附上一个超级好用的机器学习算法选择流程图:
数据科学处理
在开始考察不同ML算法之前,您首先需要搞清楚你的数据,问题和约束条件。
了解你的数据
我们所掌握的数据类型是算法选择的关键因素。一些算法可以处理较小的样本集,而有些算法则需要大量的样本,某些算法则适用于特定类型的数据。例如,NaïveBayes可以很好地处理分类输入,但对缺失的数据并不敏感。
因此,您必须:
了解你的数据
1.查看摘要统计信息和可视化信息
- 百分位可以帮助识别大部分数据的范围
- 平均数和中位数可以描述中心趋势
- 相关性可以表明强关系
2.可视化数据
- 箱形图可以识别异常值
- 密度图和直方图显示数据的散布
- 散点图可以描述双变量关系
清理你的数据
1.处理缺失的数值
数据缺失对一些模型的影响大过其他模型。即使对于能够处理缺失数据的模型,也可能很敏感(缺少某些变量的数据可能导致预测效果较差)
2.选择如何处理异常值
- 异常值在多维数据中非常常见。
- 有些模型比其他模型更不敏感。通常树模型对异常值的存在不太敏感。然而回归模型或任何试图使用方程的模型肯定会受到异常值的影响。
- 异常值可能是脏数据收集的结果,也可能是合法的极端值。
3.数据是否需要汇总
强化数据
1. 特征工程(Feature engineering)是将原始数据转换为可用于建模的数据的过程。它可以用于多种目的:
- 使模型更易于解释(例如装箱)
- 捕捉更复杂的关系(如神经网络)
- 减少数据冗余和维度(如PCA)
- 重新调整变量(例如标准化或正常化)
2.不同模型可能有不同的特征工程要求,有些已经包含在了特征工程中。
问题分类
下一步是对问题进行分类。这是一个两步过程。
1.按输入分类:
- 如果你有数据标签,这是一个监督学习问题。
- 如果您有未标记的数据并且想要查找结构,那么这是一个无监督的学习问题。
- 如果你想通过与环境交互来优化目标函数,这是一个强化学习问题。
2.按输出分类:
- 如果你的模型的输出是一个数字,这是一个回归问题。
- 如果你的模型的输出是一个类,这是一个分类问题。
- 如果模型的输出是一组输入组,那么这是一个聚类问题。
- 你想检测一个异常?这是异常检测
了解你的约束条件
- 你的数据存储容量是多少?你的系统存储容量,可能无法存储千兆字节的分类/回归模型或千兆字节的数据以进行群集。例如,嵌入式系统就是这种情况。
- 预测是否要快?在实时应用中,尽可能快地进行预测显然是非常重要的。例如,在自动驾驶中,需要以最快的速度分类路标以避免事故发生。
- 学习速度要快吗?在某些情况下,快速训练模型是必要的:有时,您需要使用不同的数据集快速更新模型。
找到可用的算法
假如你已经明确了自己所处的位置,接下来可以选择可行适用的算法,用手头的工具实施。
机器学习算法模型选择的筛选条件:
- 该模型是否符合业务目标
- 模型需要多少预处理
- 模型的准确度如何
- 该模型如何解释
- 模型的速度有多快:构建模型需要多长时间,模型需要多长时间进行预测。
- 该模型的可扩展性如何
算法选择的重要条件是模型复杂度。一般来说,模型更复杂意味着:
- 它依靠更多的功能来学习和预测(例如,使用两个特征vs十个特征来预测目标)
- 它依赖于更复杂的特征工程(例如使用多项式项,交互作用或主成分)
- 更多的计算开销(例如,单个决策树与100个决策树的随机森林)。
除此之外,参数数量或某些超参数的选择可以导致机器学习算法的复杂度增加。例如:
- 回归模型拥有更多的特征,或多项式项和交互项。
- 决策树的深度。
这些都会导致算法更复杂,进而增加过度拟合的可能性。

常用的机器学习算法(请参考:机器学习常见算法分类汇总)
线性回归
这些可能是机器学习中最简单的算法。例如,可以使用回归算法来计算某些连续值,而输出结果是分类的情况下则与分类类似。因此,无论何时当你需要对正在运行的进程进行预测时,都可以使用回归算法。然而,线性回归在特征冗余的情况下是不稳定的,假如存在多重共线性的情况。
使用线性回归的一些示例:
- 从某地去某地的时间问题
- 预测下个月特定产品的销售情况
- 血液酒精含量对协调的影响
- 预测每月的礼品卡销售量并改进年度收入预测
逻辑回归(Logistic Regression)
逻辑回归执行二进制分类,因此标签输出是二进制的。它采用线性组合的特征并对其应用非线性函数(sigmoid),因此它是一个非常小的神经网络实例。
逻辑回归提供了很多方法来规范模型,并且您不必担心与特征相关的问题,就像对待朴素贝叶斯算法一样。逻辑归回提供很好的概率解释(probabilistic interpretation),并且你可以轻松更新您的模型以接收新数据,这一点比决策树或SVM好很多。如果您需要一个概率框架,或者您希望将来能够接收更多的培训数据并且能快速将其纳入模型,请使用逻辑回归。逻辑回归也可以帮助你理解预测背后的因素,而不仅仅是一个黑匣子方法。
逻辑回归可用于以下情况:
- 预测客户流失
- 信用评分和欺诈检测
- 衡量营销活动的有效性
决策树
“独木不成林”,单一决策树的用例很少见,通常我们将多个决策树组合在一起构建更加高效算法,如随机森林(Random Forest)或梯度树增强( Gradient Tree Boosting)。
决策树可以轻松处理特征交互,而且它们是非参数化的,所以您不必担心离群值或数据是否线性分离。决策树的一个缺点是他们不支持在线学习,所以当新的样本出现时你必须重建你的树。另一个缺点是它们很容易过拟合,这时就需要使用随机森林(或增强型树)这样的集合方法。决策树还会占用大量的内存(功能越多,决策树越深越大)
决策树是帮助您在多个行动方案中进行选择的绝佳工具。
- 投资决策
- 客户流失
- 银行贷款拖欠者
- 开发vs购买决策
- 销售线索资格审验
K-means聚类算法
有时您不知道任何标签,而目标是根据对象的特征分配标签。这被称为集群化任务。例如,当有大量的用户,并且你想根据一些共同的属性将它们划分成特定的组时,可以使用聚类算法。
如果在你的问题设计如何组织或分组或如何集中特定组等问题,那么你应该使用聚类。
K-Means最大的缺点时需要事先知道数据中会有多少个簇,因此这可能需要大量的试验来“猜测”要定义簇的最佳K数值。
主成分分析(PCA)
主成分分析可用于降维(dimensionality reduction)。有时候你有很多功能,可能彼此高度相关,当数据量很大时模型很容易过拟合。这时可以应用PCA。
PCA成功背后的关键之一是除了低维度样本表示之外,它还提供了变量的同步低维表示。同步样本和变量表示使得可视化查找样本群特征变量成为可能。
支持向量机(Support Vector Machine ,SVM)
支持向量机(SVM)是一种监督式机器学习技术,广泛应用于模式识别和分类问题 – 当你的数据恰好分为两类时。
高精确度,理论上能够避免过拟合,并且在适当的内核下SVM可以很好地工作,即使你是数据也不能在基本特征空间中线性分离。处理高维空间的文本分类问题时,SVM尤其受欢迎。但是,支持向量机是内存密集型的,难以解释并且难以调试。
SVM在现实世界的用例如下:
- 检测糖尿病等常见疾病患者
- 手写字符识别
- 文本分类 – 按主题分类的新闻文章
- 股市价格预测
朴素贝叶斯(Naive Bayes )
它是基于贝叶斯定理的分类技术,非常容易构建,特别适用于非常大的数据集。简洁的同时,朴素贝叶斯的效率甚至超过高度复杂的分类方法。尤其当CPU和内存资源有限时,朴素贝叶斯是一个非常不错的选择。
朴素贝叶斯非常简单,主要工作只是计数而已。如果NB条件独立假设成立,那么朴素贝叶斯分类器将比逻辑回归等区分性模型更快地收敛,因此需要的训练数据更少。即使NB假设不成立,NB分类器在实践中仍经常表现出色。一个很好的选择,如果你只是想要一个性能优异,快速简易的算法,那么朴素贝叶斯绝对值得一试。它的主要缺点是无法学习功能间交互。
朴素贝叶斯在现实中的应用:
- 情感分析和文本分类
- 推荐系统,如Netflix,亚马逊
- 垃圾电子邮件标识
- 人脸识别
随机森林(Random Forest )
随机森林是决策树的集合体。它可以解决大数据集的回归和分类问题。它还能帮助识别数千个输入变量中最重要的变量。随机森林可高度扩展到任意数量的维度,性能表现一般也可接受。最后,还有遗传算法( genetic algorithms),对于任何维度和任何数据都有很好的扩展性,即使对数据本身知之甚少,其中一个极简化和最小化的实现就是微生物遗传算法。随机森林的缺点是,学习速度可能会很慢(取决于参数设置),并且不能对已经生成的模型进行迭代改进。
随机森林在现实中的用例:
- 预测患者高风险
- 预测制造过程中的零件故障
- 预测贷款违约者
神经网络
神经网络引入了神经元之间的连接权重。权重是平衡的,循序学习数据点。所有权重都被训练完毕后,当出现新的输入数据点的回归时,神经网络可以预测类或数量。使用神经网络,可以训练极其复杂的模型,并且可以将它们用作一种黑盒子,而无需在训练模型之前进行不可预测的复杂特征工程。加入“深度方法”后,可以产生更多不可预测模型用来预测新的可能性。例如,最近利用深度神经网络进行物体识别取得了极大的进步。神经网络被用于非监督式学习,例如特征提取,深度学习也能在无人干预的情况下从原始图像或者语音中提取特征。
神经网络的缺点是很难澄清,参数设置也非常烧脑。此外神经网络属于资源和内存密集型的算法。
机器学习算法选择流程图
最后奉上一个Scikit learning挥之的机器学习算法选择流程图,非常深入且明晰,方便好用,建议收藏(点击查看大图)。
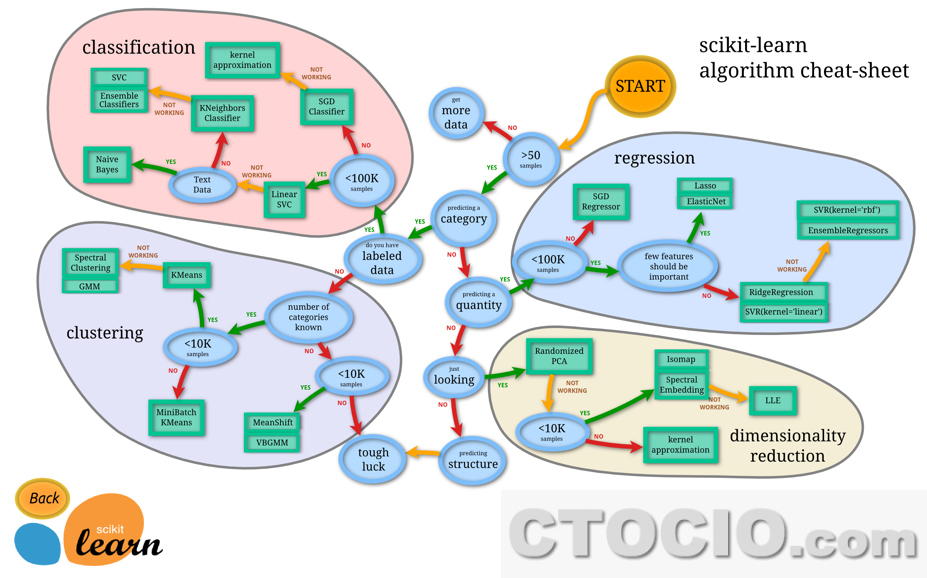
(http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html)
结论
您可以根据以上几点来简要筛列一些算法,但通常人们很难从一开始就知道哪种算法最适合,最好是迭代尝试。敲定候选机器学习算法后,输入数据,并行或串行地运行算法,最后评估算法的性能并选择最好的一个(或多个)。
最后,为解决现实生活问题开发解决方案绝不仅仅是一个应用数学问题。你需要了解业务需求,规则和法规,利益相关者诉求以及相当的专业知识。
本文作者:Rajat Harlalka , Entrepreneur | Operating Partner at GSF
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者CashCat

















