顶级大模型的“脑容量”只有1TB?

AI大模型用户经常会有这样的困惑:“它是真理解了我说的话,还是在背诵/拼凑曾经见过的内容(训练数据)?”这个问题困扰了整个 AI 行业多年——大模型的回答真的是基于“推理能力”,亦或只是“训练数据太多、记忆力太强”?
这个问题不仅关乎 AI 的能力评估,数据安全防护,更是未来生成式AI版权官司的核心战场:如果模型只是“背过的内容照搬出来”,那版权法就有用武之地;但如果它是在泛化理解之后生成内容,AI公司或许可以“合理使用”来逃脱责任。
最近,Meta、Google DeepMind、英伟达和康奈尔大学联合发布了一项研究(论文链接在文末),用严谨的实验方法首次精确计算出:GPT类大模型平均每个参数只记住了 3.6 比特的信息。这个数字,或将成为衡量“模型记忆能力”的行业新基准。
大模型“记忆力”的极限测试
为了测量模型的“纯记忆能力”,研究团队并没有用自然语言训练模型——因为语言有规律、重复性,模型可能是靠推理得出结果,而非记忆。
相反,他们设计了一种极限测试方法:用完全随机、无任何结构的比特串来训练 Transformer 模型。这些数据就像乱码,没有语义、没有重复、无法压缩,是AI完全无法“推理”的对象。模型唯一能做的就是死记硬背。
通过这种方法,他们首次把“记忆”与“泛化”彻底分离了开来:模型对这些随机串的学习能力,正是它最真实的“记忆容量”体现。
3.6 比特/参数:AI模型的“脑容量”原来这么小
那么,3.6比特到底意味着什么?这是一个看似微不足道的数字,但它背后的意义巨大:
一个模型如果有 1.5 亿个参数,就大概只能记住 675MB 的信息;目前市场上主流的大模型的“脑容量”大致推算如下:
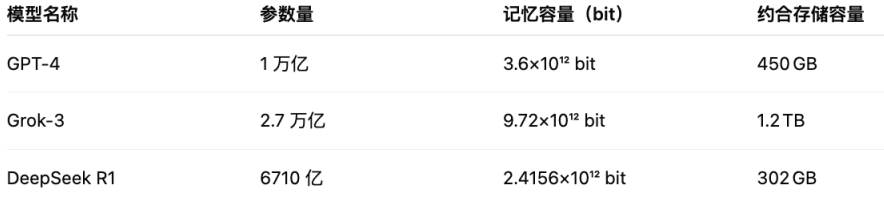
可以看出,参数量较大的Grok-3的“脑容量”也不过才1TB多,这比起硬盘存储来说微不足道(但对于文字数据来说,已经能存下大量句式、结构和短文段。)
这意味着,即便你把整个互联网都喂给一个模型,它也只能记住其中极小的一部分。
这套测试方法也验证了:即便更换模型深度、宽度、精度(如 float32 vs bfloat16),这个记忆容量数值依然稳定,充分说明这是一个结构独立、可通用的“底层物理属性”。
吃得越多,记得越少?反直觉的大模型训练法则
最令人震撼的发现是:大模型吃得越多,反而记得越少。
是的,你没看错。模型的“记忆总容量”是固定的,因此数据集越大,每个样本平均分到的“记忆额度”就越小。这意味着:
训练数据越多,模型越不容易完整记住某一个样本。
这一发现对AI隐私安全极具意义。它意味着:只要数据足够多、足够广泛,AI 模型泄露具体内容的概率实际上是下降的。也就是说,大模型不是“吃得多就越危险”,而是“吃得少才更可能抄袭”。
模型“偏爱”记忆独特内容
不过研究者也坦言:尽管平均记忆风险降低了,但一些“独特性”极强的数据,比如诗歌、个人风格明显的写作、独家代码,仍然有可能被模型记住。
这就像在大海里撒网,虽然每条鱼被抓住的概率都很低,但那条颜色特别、游得最慢的鱼,仍然可能落网。
这部分研究虽然强调的是“平均趋势”,但对版权方和敏感数据拥有者来说,仍需保持警觉。未来模型防泄露设计,可能会优先对“独特数据”加强保护。
“AI记忆量化”成版权诉讼焦点
对于正在全球范围内展开的针对人工智能公司的 AI 版权诉讼来说,这项研究无疑是一根“救命稻草”。
比如,如果 OpenAI、Anthropic 或 Google 被指控“非法复制作品”,他们就可以援引本研究结论:模型的记忆是有限的、非结构化的,而且数据越多越难记忆某一具体作品。
这正好呼应美国法律对AI“合理使用”定义的核心逻辑——如果机器生成的内容不是“机械复制”,而是“创作性地再现统计规律”,那么很可能不构成侵权。
而未来法院是否接受这样的技术论证,也将直接决定 AI 训练合法性的边界线。
训练精度的误区:32位更“聪明”?回报不成正比
研究还探索了另一个维度:训练精度对模型记忆力的影响。他们发现,虽然将精度从 bfloat16 升到 float32,模型记忆能力仅略有提升(从 3.51 到 3.83 bits/参数),但收益远远小于理论预期。
这说明:即便你把模型的“每颗脑细胞”做得更精致,它整体“记性”并不会暴涨,反而出现“边际效益递减”。
对于想通过提高精度来规避版权风险或提升泛化能力的公司来说,这也是一个及时的提醒:大模型的智商,不一定用钱能砸出来。
可能改写 AI 训练范式
这项研究,不只是解答了“模型记忆多少”这个老问题,更可能成为 AI训练设计、隐私防护、法律合规、模型评估标准的基础。
未来我们可能会看到如下趋势:
- 模型训练透明化:开发者需证明“没记住用户数据”;
- 数据供应方议价力提升:哪些内容容易被记住,哪些构成高价值,将变成关键判断依据;
- 模型架构更倾向泛化优化:不是压榨记忆力,而是提高泛化效率;
- “可解释性”与“记忆压缩率”并重:用3.6 bits装下更多知识,成为新课题。
总结:AI 不是“硬盘”,但它能做“统计魔术师”
这篇研究的最大意义在于,它帮助人类第一次用明确的数字,理解了“AI的记忆力”。
大模型并不是简单地“看过就会抄”,它也不是一个完美压缩的“互联网备份盘”。它更像一个“模糊统计学家”——它记住的是万千样本的“轮廓”,而非每个细节。
而我们,作为模型使用者、数据提供者、网络安全人士、法律制定者,也许需要开始基于这种更科学的理解(如果该研究结果被广泛验证),重新设计未来的 AI 治理、开发和应用规则。
参考链接:
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者GoUpSec
升华安全佳,安全看世界。GoUpSec以国际化视野服务于网络安全决策者人群,致力于成为国际一流的调研、分析、媒体、智库机构。

















