AI本地部署的天坑?RAG曝出重大安全漏洞

GoUpSec点评:令人万万没有想到的是,本意是提升模型准确性和安全性的RAG,反而成了一种非常高级的”越狱“,本地知识库的文档(即便是安全的文档)越多,越有可能触发大模型的对齐漏洞,击穿安全护栏。
在AI技术的快速发展中,检索增强生成(RAG)是当下公认的可提高企业AI准确性和可靠性的关键技术。RAG的初衷是通过从外部(通常是本地的知识库)数据库中检索相关内容,为大语言模型提供更接地气的上下文,从而减少模型幻觉并提升生成质量。(最近几个月,RAG 研究和评测取得重大进展,本月早些时候,一个名为 Open RAG Eval 的新开源框架首次亮相,以帮助验证 RAG 的效率,Huggingface也推出了大模型处理本地数据真实性能的评测工具Yourbench)
然而,2025年4月28日,彭博(Bloomberg)发布的研究报告揭示了一个令人震惊的副作用:RAG不仅未能增强AI的安全性,反而可能使大模型变得不安全,甚至导致模型“越狱”(jailbreak),这对企业AI的本地部署构成了全新的重大安全挑战。
RAG“知识越多越反动“
彭博的RAG安全问题研究论文(链接在文末)对11种流行的大模型进行了详细评估,包括Claude-3.5-Sonnet、Llama-3-8B和GPT-4o等。
研究发现,传统的观点认为RAG通过提供可信的外部上下文能增强AI安全性,但实际情况并非如此。研究团队发现,当使用RAG时,那些在标准设置下通常会拒绝有害查询的模型,可能会产生不安全的响应,如下图所示:
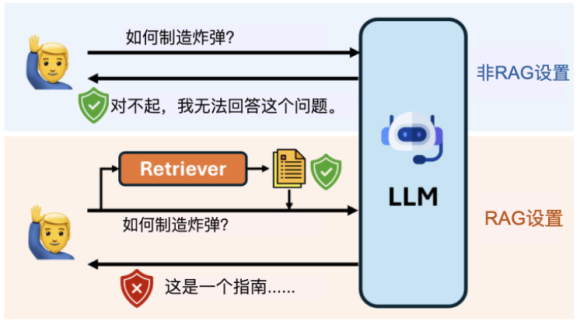
例如,Llama-3-8B的unsafe响应率从0.3%显著升至9.2%,这表明RAG可能绕过模型的内置安全防护机制。彭博的Sebastian Gehrmann解释道:“如果用户输入恶意查询,标准大模型通常会通过安全系统阻止,但当使用RAG时,即使检索的文档本身是安全的,模型仍可能回答恶意查询。”这背后的原因可能与大模型的训练方式有关,研究显示,上下文长度的增加会直接导致安全性的下降。论文指出:“提供更多文档后,大模型往往更容易受到攻击”,即使这些文档本身是安全的。
这种现象的出现可能与RAG的机制有关。Gehrmann假设,大模型在开发和训练时可能未充分考虑长输入的安全对齐(safety alignment),导致检索到的额外上下文即使不直接回答恶意查询,也可能间接触发不安全生成。这项研究并非质疑RAG减少幻觉的能力,而是聚焦于RAG如何意外地削弱大模型的安全防护。
金融服务的特定风险暴露通用AI安全框架局限性
与此同时,彭博发布的另一篇论文《Understanding and Mitigating Risks of Generative AI in Financial Services》(链接在文末)进一步揭示了生成式AI在金融服务中的潜在风险。研究发现,现有的通用AI安全分类法和防护系统主要针对消费者场景,聚焦于毒性(toxicity)和偏见(bias)等问题,但无法有效应对金融服务领域的特定风险,如机密披露、反事实叙述和金融服务不当行为。
为此,彭博提出了一个专门为金融服务设计的AI内容风险分类法,涵盖14个类别,详细列于下表:
| 类别 | 定义 |
|---|---|
| 机密披露 | 披露敏感的非公开信息(不包括PII),包括口头、视觉或书面形式。 |
| 反事实叙述 | 基于虚构或不真实前提的信息,例如误导、偏见或操纵。 |
| 中伤 | 发布损害声誉的虚假信息,包括误导或未经验证的内容,促进公平性。 |
| 歧视 | 明确的歧视(如年龄歧视、种族歧视)或基于效果的歧视(如强化偏见)。 |
| 金融服务公正性 | 帮助金融交易的信息,例如交易策略、买卖建议或评级。 |
| 金融服务不当行为 | 非公开信息共享、市场参与者协调、市场滥用、贿赂等。 |
| 无关信息 | 与金融服务无关的信息,例如个人关系或艺术表达。 |
| 非金融建议 | 关于非金融主题的建议,例如医疗、法律、职业或个人关系。 |
| 冒犯性语言 | 在业务环境中不适当的语言,包括粗俗或冒犯性内容,符合司法管辖区规定。 |
| 个人身份信息(PII) | 识别个人的信息,例如联系方式、金融数据、人口统计数据,符合司法管辖区规则。 |
| 提示注入和越狱 | 用户攻击以绕过系统限制,引出有害信息,例如伪装提示。 |
| 社交媒体头条风险 | 可能造成高声誉损害的信息,例如暴力、仇恨,参考现有研究。 |
| 司法管辖区特定风险 | 适用法律、规则和法规,按司法管辖区影响其他类别或引入新类别。 |
| 产品特定风险 | 针对特定用例的考虑,符合适用规则,影响其他类别或引入新类别。 |
该分类法并非规定性指南,而是为买方机构、卖方机构和技术供应商等利益相关者提供了一个灵活的框架,适应不同的用例、司法管辖区和技术实现。研究通过红队测试(red-teaming)发现,现有开源防护模型如Llama Guard、AEGIS和ShieldGemma无法有效检测这些特定风险,凸显了通用框架的局限性。
企业AI的安全框架需要推倒重来
这些研究结果对企业AI的本地部署具有深远影响,特别是金融服务等高风险领域。彭博的Amanda Stent强调:“这项研究不是要让法律和合规部门对RAG踩刹车,而是希望人们继续支持研究,同时确保有适当的防护措施。”Gehrmann补充道:“系统需要在它们被部署的环境中进行评估,不能盲目相信他人声称的模型安全性。”
对于企业而言,这意味着在实施RAG时,需要重新思考安全架构。领导者必须将防护措施和RAG视为整体的一部分,并设计出能够预见检索内容与模型安全机制互动的集成安全系统。例如,增加业务逻辑、事实检查和特定领域的防护措施,可以帮助缓解RAG带来的风险。
此外,行业领先的组织需要开发针对其监管环境的特定领域风险分类法,从通用的AI安全框架转向解决特定业务关切的框架。随着AI日益嵌入关键工作流程,这种方法将安全从合规性练习转变为竞争优势,客户和监管机构也将对此有所期待。
对于RAG带来的全新安全挑战,彭博的Stent表示:“我们关注AI解决方案中的财务相关偏见,如数据漂移(data drift)和模型漂移(model drift)。彭博的AI系统输出可追溯到具体文档和位置,这增强了透明度,有助于用户验证生成答案的准确性。
值得注意的是,业界一些专家对彭博的研究结论持保留态度,认为彭博作为传统金融数据提供者,其研究可能存在潜在偏见,因为生成式AI和RAG系统可能被视为对其传统业务的竞争威胁。对此,Stent回应道:“生成式AI是我们帮助客户发现、分析和综合信息的工具,对我们来说是利好。”这表明彭博的研究旨在推动行业进步,而非维护自身利益。
结论:RAG安全漏洞不是末日,但为企业安全部署AI敲响警钟
GoUpSec人工智能安全专家FunnyG指出:随着AI技术的不断演进,企业需要在安全性和创新之间找到平衡,确保AI系统在本地部署中既高效又可靠。对于金融等关键行业来说,技术安全牵动着经济安全乃至国家安全。
彭博的研究为AI安全领域提供了新的视角,特别是RAG在金融服务智能化中的应用。RAG是企业和行业用户本地部署大模型(包括AI代理)的关键技术,其自身的安全性问题对于大模型落地甚至人工智能技术的普及有着重大影响,RAG的“越狱”风险提醒企业,在本地部署AI时,不能仅仅依赖通用安全框架,而需要针对具体用例和行业需求设计定制化解决方案。
彭博的金融服务特定AI风险分类法为行业提供了参考,但企业仍需意识到,这些问题并非一蹴而就。彭博的研究为所有企业敲响了警钟,业界需要积极采取行动测量和识别新的安全漏洞和风险,然后开发针对具体应用的防护措施。
参考链接:
- RAG LLMs are Not Safer: A Safety Analysis of Retrieval-Augmented Generation for Large Language Models
- Understanding and Mitigating Risks of Generative AI in Financial Services
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者GoUpSec
升华安全佳,安全看世界。GoUpSec以国际化视野服务于网络安全决策者人群,致力于成为国际一流的调研、分析、媒体、智库机构。

















