顶流人工智能距离“通用”还很遥远
近日,研究人员实用GAIA 的新人工智能基准评估 ChatGPT 等聊天机器人是否能够在日常任务中表现出类似人类的推理和能力,结果令人大跌眼镜,最新的人工智能技术在处理通用任务时,与人类的表现相去甚远。
该基准由 Meta、Hugging Face、AutoGPT 和 GenAI 的研究人员创建,“提出了需要一系列基本能力的现实世界问题,例如推理、多模态处理、网页浏览和一般工具使用熟练程度”,研究人员在 arXiv 上发表的一篇论文中写道。
研究人员表示,GAIA 问题“对于人类来说在概念上很简单,但对于最先进的人工智能来说却具有挑战性”。他们对人类受访者和 GPT-4 进行了基准测试,发现人类得分为 92%,而带有插件的 GPT-4 得分仅为 15%。
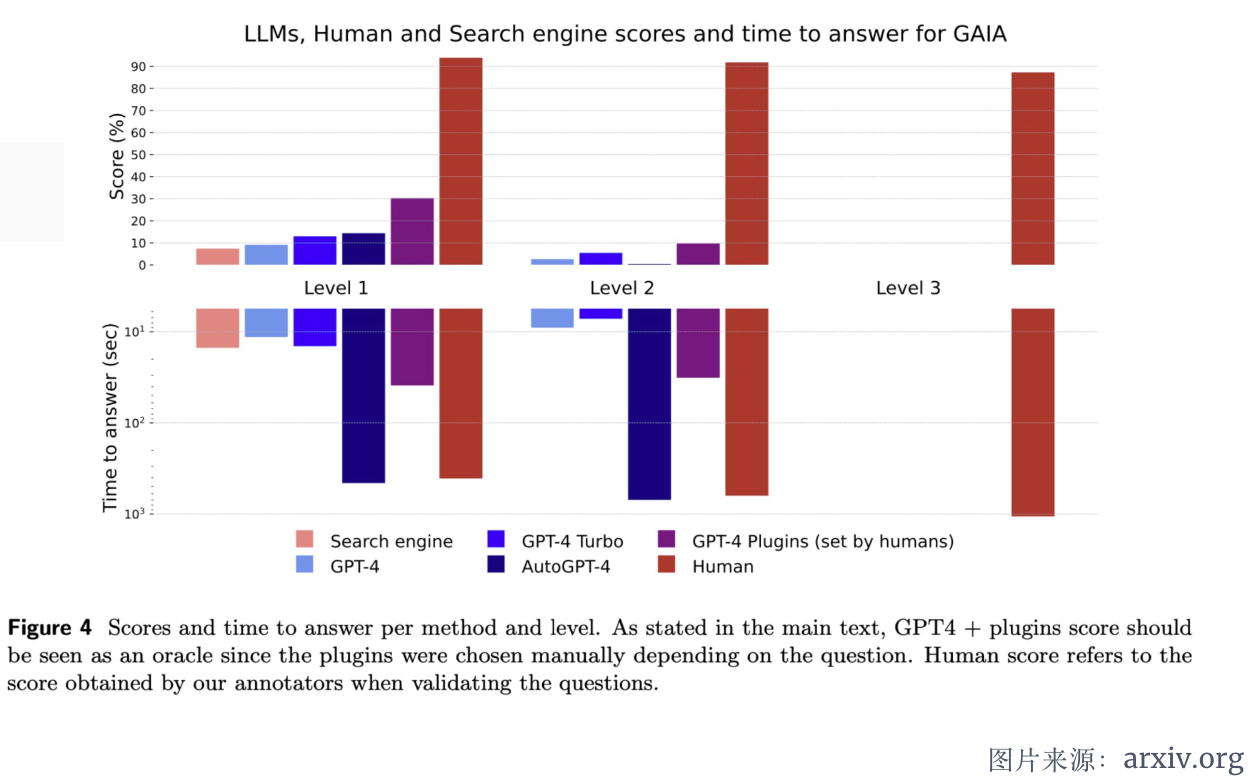
“在日常任务测试中的显著性能差异与最近的趋势形成鲜明对比,LLM(大型语言模型)在需要法律、化学等专业技能的任务上表现优于人类。”论文指出。
研究人员认为,基准测试应该针对那些能够证明人工智能系统与普通人具有相似鲁棒性的任务,而不是专注于人类难以完成的任务。
GAIA 方法引导研究人员设计了 466 个现实世界的问题,并给出了明确的答案。300 个答案被私下保存,为公共 GAIA 排行榜提供动力,同时 166 个问题和答案作为开发集发布。
Meta AI 的主要作者 Grégoire Mialon 表示:“解决 GAIA 问题将代表人工智能研究的一个里程碑。” “我们相信 GAIA 的成功解决将成为下一代人工智能系统的一个重要里程碑。”

人类与人工智能的性能差距
到目前为止,领先的 GAIA 分数属于带有手动选择插件的 GPT-4,准确率为 30%。基准开发者表示,在合理的时间范围内解决 GAIA 问题的系统可以被视为通用人工智能。
该论文批评了在复杂的数学、科学和法律考试中测试人工智能的常见做法,指出“对人类来说困难的任务对于最新的人工智能系统来说未必是困难任务(编者:参考自动驾驶面临的困境)”。
相反,GAIA 专注于诸如“根据官方网站,哪个城市主办了 2022 年欧洲歌唱大赛?”“2022 年最新的乐高维基百科文章中有多少张图片?”之类的问题。
研究人员写道:“我们认为通用人工智能(AGI)的出现取决于系统在此类问题上表现出与普通人相似的鲁棒性的能力。”
GAIA 塑造人工智能未来轨迹
GAIA 的发布代表了人工智能研究的一个令人兴奋的新方向,可能会产生广泛的影响。通过关注日常任务中类似人类的能力而不是专业知识,GAIA 推动该领域超越了更狭隘的人工智能基准。
如果未来的系统能够展现出 GAIA 所衡量的人类水平的常识、适应性和推理能力,则表明它们将实现实际意义上的通用人工智能( AGI )。这可以加速人工智能助手、服务和产品的部署。
然而,作者警告说,今天的聊天机器人在解决 GAIA 问题上还有很长的路要走。他们的表现显示了当前在推理、工具使用和处理各种现实情况方面的局限性。
随着研究人员应对 GAIA 挑战,他们的研究结果将揭示人工智能系统在变得更强大、更通用和更值得信赖方面取得的进展。但像 GAIA 这样的基准也会引发人们对如何塑造造福人类的人工智能的反思。
研究人员写道:“我们相信 GAIA 的成功解决将成为下一代人工智能系统的一个重要里程碑。” 因此,除了推动技术进步之外,GAIA 还可以帮助引导人工智能朝着强调人类共同价值观(如同理心、创造力和道德判断)的方向发展。
您可以在此处查看GAIA 基准排行榜,了解哪个下一代 LLM 在评估中表现最佳。
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者Cashcow
隐私已经死去,软件正在吃掉世界,数据即将爆炸

















