AI 泡沫的致命漏洞:大模型不是真正的智能

点评:维特根斯坦一句“语言的边界是世界(思想)的边界”,支撑起了一个估值高达数万亿美元的人工智能产业。但是,万一这句话是错的呢?
华尔街和硅谷的空气里此刻正弥漫着通用智能降临前的宿命气氛。
马克·扎克伯格高呼“通用超智能已经在望”,Anthropic 的 CEO Dario Amodei 则坚信,“到 2026 年,AI 在多数重要领域将比诺奖得主更聪明”;而 Sam Altman 更是激进地宣称,OpenAI 已经握住了通往 AGI(通用人工智能)的钥匙,即将借此加速全人类的科学发现。
听上去,我们正站在一场“技术神迹”的门槛上。但如果你从这些宏大叙事中抽身,哪怕只是认真审视一眼当下最强大的模型,无论是 ChatGPT、Claude 还是 Gemini,一个冷冰冰的事实就会浮出水面:
它们本质上只是“超大型语言补全机”,而非真正的“通用智能”。
这并非对技术的傲慢,也不是情绪化的反驳。这是神经科学、认知心理学以及 AI 行业内部那些冷静的“反叛者”们共同指向的结论。那个正在被数万亿美元撑起的 AI 泡沫,其逻辑深处最致命的漏洞,恰恰就埋在这个不起眼的认知错位里:我们混淆了“说话流畅”与“真正思考”。
语言的假象:它在拟合,而非思考
今天被捧上神坛的大语言模型(LLM),底层逻辑其实朴素得令人惊讶。
无论它们被包装成“全能助手”还是“虚拟科学家”,其核心运作机制只有一个:将互联网时代积累的海量文本(token)吞噬殆尽,学习这些字符之间复杂的统计关联,然后当你给出一个提示词时,预测“下一个最可能出现的词是什么”。
换句话说,这是一场关于概率的游戏。The Verge 曾一针见血地指出,这些系统本质上是“语言模式的统计预测器”。它们最擅长的事情,是给你一段上文,然后补全一个“看起来极像人类所写”的下文。
这当然是一种惊人的能力。当算力被堆叠到天际,数据量达到极致,量变引发了质变。它们写出的代码、邮件、甚至十四行诗,足以让大多数人类汗颜。但这里存在一个巨大的认知陷阱:会补全句子,并不等于会思考。
要看清这个差别,我们需要回到一个更本质的问题:在人类的大脑里,语言和智力,到底是一回事吗?
神经科学的“坏消息”:语言并非思维的本体
长期以来,我们有一种直觉:语言是思维的载体,甚至语言就是思维本身。但神经科学最新的研究,正在无情地拆解这个直觉。
去年,麻省理工学院(MIT)的 Fedorenko 教授联合多位学者在《自然》杂志发表了一篇极具分量的文章,标题很直白:“语言主要是沟通工具,而不是思维本身。”
这项研究通过功能磁共振成像(fMRI)技术,向我们展示了大脑内部精妙的分工(下图):
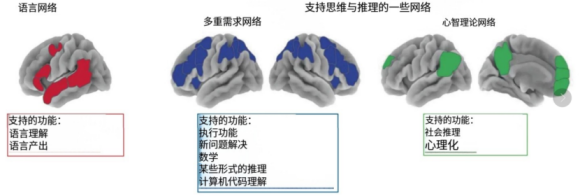
当我们处理语法和词汇时,大脑中一个特定的“语言网络”会被激活;但当我们解数学题、进行逻辑推理或解决复杂问题时,忙碌的却是另一个完全不同的区域——“多重需求网络”。而在揣摩他人意图、进行社交推理时,负责的又是“心智理论网络”。
这两个系统在空间和功能上是高度分离的。最极端的证据来自那些不幸患有失语症的病人。研究发现,即便脑损伤导致一个人的语言能力严重受损,甚至完全无法说话或理解句子,他依然可能保留解数学题、进行因果推理、通过图像理解他人意图的能力。
这一结论对当前的 AI 路线是毁灭性的:既然把人类大脑里的“语言模块”拔掉,人依然能思考,那么反过来说,仅仅在机器里把“语言模块”堆到极致,并不意味着你就造出了一个会思考的大脑。
这一点在婴儿身上同样得到了印证。发展心理学家 Alison Gopnik 的研究显示,在学会说话之前,婴儿就已经是一个个“小科学家”了。他们通过观察、试错、统计与修正,在脑海中构建对物理世界和他人意图的直觉理论。语言后来不仅没有创造这些认知,反而是依附于这些认知之上,成为一种分享和加速的工具。
而现在的 LLM 在做什么?它们在语言这条单一的支线上狂飙突进,在大脑的“语言网络”维度上堆出了一个庞然大物,但在“多需求网络”和“心智理论网络”所对应的推理、规划、感知能力上,却依然是空心的。
行业内的“反叛”:从神话回归常识
有趣的是,连 AI 行业内部的精英们,也开始难以维持“只要把模型做大就是 AGI”的叙事了。
最显著的信号来自 Yann LeCun。作为 Meta 的首席 AI 科学家和图灵奖得主,他最近宣布将精力投向一家新创业公司,核心目标直指 LLM 的软肋。LeCun 直言不讳:纯靠大语言模型的路线,不足以带来真正的人类级智能。他所推崇的未来是“世界模型(world models)”——一个能理解物理规律、拥有持久记忆、能进行长链条推理和规划的系统。
这其实是在补课。行业正在意识到,AI 需要从“会讲故事”进化到“知道世界如何运作”。
今年,一个由图灵奖得主 Yoshua Bengio 等大佬组成的小组,更是给“通用人工智能”列出了一张残酷的体检表。在这个包含知识、语言理解、推理、感知、记忆、规划等十个维度的“蜘蛛网指标”(下图)中,当前的主流模型虽然在“知识”和“语言”上得分惊人,但在长期记忆、稳健推理和真实世界感知上却严重“偏科”。

甚至连曾经高喊“2026 年超越诺奖得主”的 Dario Amodei,最近也在采访中松口,承认“AGI”这个词更多是一种营销术语。这听起来,就像是给两年来高烧不退的 AI 泡沫写下的一份含蓄的悔过书。
致命的局限:困在“死去的隐喻”里
为什么单纯堆砌文本数据,无法涌现出真正的智能?
哲学家理查德·罗蒂曾说:“常识其实是一堆已经死掉的隐喻。”真正的创新,往往源于对既有常识的不满,源于发明新的隐喻来重新描述世界。
大模型的困境恰恰在于此。它们的训练目标是“预测下一个最可能的词”,也就是在海量的语料中寻找既有的统计结构。这使得它们成为一个极致的“常识仓库”或“陈述性知识库”。
但人类智能中大量至关重要的部分是“程序性”和“情境化”的。你是如何学会骑自行车的?你在谈判桌上如何读懂对手那个转瞬即逝的微表情?你是如何感知深夜小巷里那种“不对劲”的氛围?这些知识从未被完整地写进书本,也就从未被模型真正习得。
更深层的问题在于创新。科学哲学家库恩曾提出“范式转换”的概念。爱因斯坦提出相对论,并不是在牛顿力学的旧书堆里通过统计关联“算”出来的,而是他跳出了旧有的叙事坐标,建立了一套全新的解释框架。
而 LLM 的工作机制决定了,它是在“把现有的知识和隐喻压榨到极致”。它没有对常识感到“不满”的动机,也没有跳出训练数据分布的机制。因此,它能写出一篇完美的相对论科普文章,却很难在没有数据投喂的情况下,成为下一个爱因斯坦。它在已知分布内无比流畅,但在未知领域却寸步难行。
泡沫的根源:错把工具当物种
当我们理解了这些,再看当下的资本狂欢,一种巨大的错配感油然而生。
过去两年,全球科技巨头将数百亿美元砸向数据中心,把 GPU 视为新时代的石油。支撑这一切的叙事逻辑是:“我们在创造一个新物种”。如果你相信 LLM 等于通用智能,那么这些投入就像当年铺设电网一样,是通向未来的基建。
但如果 LLM 本质上只是一个“超强语言界面”加上“人类知识压缩机”,那么它更像是一个超级搜索引擎,或者一套极致自动化的 Office 套件,而不是通往超智能文明的门票。
这就是泡沫的核心:我们用“新物种”的宏大叙事,在给“语言自动化工具”定价。
从商业角度看,大模型无疑是成功的,它将深刻改变内容生产、编程和客服等行业。但这属于生产关系的升级,而非生产力形态的颠覆。真正的问题是,仅仅靠“写字、写代码、画图”这些功能,能否撑起如今对算力、芯片和未来市值的全部想象?
如果未来十年我们发现,AI 更多是让我们工作更快的工具,而不是接管世界的“新人类”,那些被炒上天际的资产又该如何重估?
对于普通的旁观者而言,也许现在是时候给大脑做一点“降噪”处理了。我们可以欣然使用这台史上最强的“知识压缩机”,享受它带来的便利,但不必急着把它供上神坛。真正的智能革命——那个能感知、能行动、能像人一样在复杂世界中推理的“世界模型”,或许还在更远的未来等待着我们。
参考链接:
- https://www.nature.com/articles/s41586-024-07522-w
- https://www.theverge.com/ai-artificial-intelligence/827820/large-language-models-ai-intelligence-neuroscience-problems
- https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web
第一时间获取面向IT决策者的独家深度资讯,敬请关注IT经理网微信号:ctociocom

除非注明,本站文章均为原创或编译,未经许可严禁转载。
相关文章:
关于作者GoUpSec
升华安全佳,安全看世界。GoUpSec以国际化视野服务于网络安全决策者人群,致力于成为国际一流的调研、分析、媒体、智库机构。

















